AI Agribench from the U of Illinois
GenAI in Agriculture Consortium


Welcome to another edition of “Software is Feeding the World.” This week’s edition will take a first look at the GenAI Benchmark announcement done by the University of Illinois and provide an update on the SFTW Convo series.
Announcements
- Most enterprise GenAI projects get stuck in proof-of-concept land. SFTW released a white paper on Wednesday, which provides a practical guide on how to break through the POC wall with case studies from four different organizations. You can get the free white paper here: “POC to OMG! The Realities of Deploying GenAI at the Farm Gate.” There have been 538 downloads of the paper. Don’t miss out by getting your free copy today!
- Rhishi Pethe will be chairing the opening fireside chat at the pre-summit at the “AI in agriculture forum” on March 10th.
- Rhishi Pethe will be hosting the inaugural AgTech Alchemy Summit on March 10th along with other AgTech Alchemy co-founders (Sachi Desai, and Walt Duflock.)
- Rhishi Pethe will be chairing the “AI / GenAI: Transforming Legacy Industries to Improve Customer Outcomes” breakout session on March 11th at the World Agritech Summit with Pratik Desai (Kissan AI), Sachi Desai (Bayer), and Stewart Collis (Gates Foundation)
GenAI Benchmark consortium for agriculture announcement
I am quite skeptical of standards and benchmarks, especially if they are enforced by fiat. When I spent a significant amount of time in logistics and transportation, everyone talked about the EDI X12 “standards”, but as soon as you dug into it, there was very little which was standard about it. There are very few universal standards and protocols like HTTP, TCPIP etc.
Many people bemoan the lack of data interoperability standards within agriculture. As always, the issue with the lack of standards is not that people don’t want standards, but it is more about the value they can create through an exchange of data and information. The talk of standards always reminds me of this classic XKCD comic:

Source: https://xkcd.com/927/
I am probably less skeptical about benchmarks. I become quite skeptical when benchmarks do not reflect real-world use cases, or they are not domain specific benchmarks. Benchmarks are also not useful if they do not measure model limitations.
G. Bailey Stockdale has been publishing scores on how different foundation LLMs perform on a standard certified crop advisor test here in the US. He has been using the CCA test to see how different models perform and improve over a period of time.
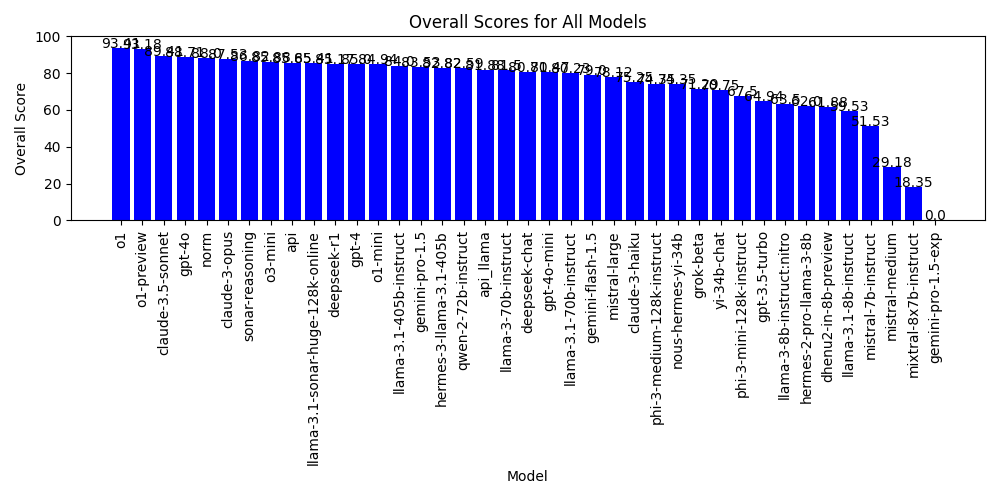
For example, ChatGPTs o1 model gets a score of 93, whereas Norm from FBN gets a score of 87. As G. Bailey Stockdale said in his post, these “tests” are not sufficient because they do not test the model in the context of the potential use cases. His goal is to spur a discussion to get the industry to think about effective “benchmarks” and he is careful to call them “scores” and not benchmarks.
Agriculture is highly context dependent. If the benchmark is done outside of specific contexts, it is very challenging to understand how to use the benchmark data. For example, should a company wanting to build their own LLM based product use o1 (93 score) as the starting point or should they use o1-mini (84 score)?
For example, Bayer’s E.L.Y. and some of its initial capabilities are able to provide accurate and reliable information from crop protection labels. The labels are for Bayer products and these labels are available in the public domain. Bayer is also working on providing seed level data.
Syngenta’s Crop Advisor tool includes GenAI capabilities for providing information about Syngenta seed products and general agronomy advice.
Digital Green’s Farmer.Chat had to be tuned to work with different languages.
The effectiveness of a model is dependent on latency / speed, cost efficiency, and accuracy of the model. Benchmarks do not account for the user experience to measure engagement and user trust, which are critical for adoption and scaling of any GenAI based product. What Bailey Stockdale is doing is a good start, but what is needed is to understand how to benchmark and what kind of data is needed to uncover the complexity of agronomy or any other decision making domain.
Many of the responses to agronomy related questions are context dependent. In this case, how do you establish a generic benchmark which works across different contexts? How should one go about creating an agronomy benchmark for GenAI models and what problems should it solve?
The University of Illinois Center for Digital Ag Announced a New Generative AI Benchmarking Consortium called AI AgriBench. The initial members of the consortium are Bayer Crop Science, Kissan AI, and the Extension foundation.
“The overarching goal of this effort is to provide farmers, policymakers, and the public with trustworthy mechanisms to evaluate and achieve high confidence in the new generation of AI-driven agronomy tools. We need to ensure these services deliver on their promise of valuable and accurate technical information to farmers and ag professionals worldwide.
Evaluating the accuracy of AI-driven question-answering services for agriculture is as important as it is technically challenging. The accuracy of such services is critical because farmers’ livelihoods and farm environments can be compromised by inaccurate or ineffective advice on crop management questions. The CropWizard project within AIFARMS is developing innovative benchmarking methods for achieving high confidence in such services. A detailed description of the evaluation methodology, data sets, and governance process will also be publicly available.”
This is a commendable effort, and at the same time for it to be effective it should be able to answer a few key questions for other GenAI based application developers in agriculture.
Nomenclature
The benchmark should try to create a common language and framework for the Agriculture AI community to make it easier to share results, replicate experiments, and build on each other’s work.
Context setting
Given how much of agronomy and other aspects of agriculture are context dependent, the benchmark should provide clear guidance on the types of data sets used, the contexts within which the benchmark is valid, and the dimensions along which the context is defined. This will help an independent GenAI based agriculture application developer understand how their model performs as they will understand their context the best and they can compare and contrast it with the benchmark’s context.
Performance Metrics
Provide standardized metrics to measure GenAI model performance across cost, latency, accuracy, coherence, reliability etc. It will allow an objective assessment of how well a generative AI model performs and can allow for consistent side by side (arena) comparisons across different models or versions of the same model.
Third party developers should be careful not to use these benchmarks as targets blindly, but should use them to understand the context, identify limitations, and build user trust. Remember Goodhart’s Law is real and all of us are susceptible to it.

https://sketchplanations.com/goodharts-law
Methods
As the news release says, the consortium will publish detailed descriptions of evaluation methodology, data sets, and governance processes. This will be hugely important to third party developers so that they don’t have to reinvent the wheel every time they want to build a GenAI based product.
Limitation Identification
Benchmarks should expose gaps or flaws, like biases and hallucinations or identify performance metrics based on different sub-domains and tasks. For example, the benchmark can say, it performs well on commodity row crops like corn in the midwest context, but does not do so well in the cotton context in the southern United States. This guides developers to understand where to focus their optimization efforts.
User Trust and Adoption through Real World Applicability
Reliable benchmarks can demonstrate a model’s capabilities to end users or businesses, fostering confidence. By simulating real-world tasks, benchmarks ensure that models are useful for practical applications like applied agronomy. Given user trust is one of the biggest roadblock to adoption, reliable and trustworthy benchmarks can build confidence in GenAI based products in general.
The decision by these organizations to establish a consortium shows leadership. The effectiveness of the consortium will depend on driving meaningful change, creating awareness and education, and ultimately adoption by the broader community. SFTW will cover this topic in more detail as more details emerge about the consortium.
SFTW Convo Series
The SFTW Convo series has kicked into high gear and I have received a lot of good feedback. I already have done 9 editions in the last 4 months. The goal of the series is to get inside the minds of leaders to understand how they think, what frameworks they use, and how they make decisions. Some of the future guests on the SFTW Convo series include, Mark Brooks (ex-VC at FMC Ventures), Shubhang Shankar (current VC at Syngenta Ventures), Kurtis Charling (VP of Product Management at Lindsay Corporation), and Tracey Wiedmeyer (CEO of Gripp).
The three most popular conversations so far have been with Matt Percy of Deere, Mike Stern (ex-CEO of The Climate Corporation), and Doug Sauder of Deere.
 Rhishi Pethe
Rhishi Pethe Rhishi Pethe
Rhishi Pethe Rhishi Pethe
Rhishi Pethe
If you want me to have an SFTW Convo with a specific person, please send me a note with the name and why they would be a good fit for SFTW. As a reminder, SFTW focuses on providing analysis on technology and innovation within the Agrifood sector.