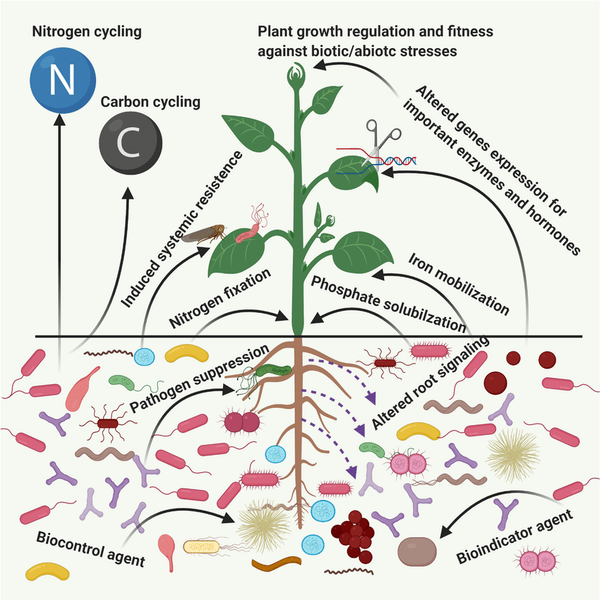
A Data Scientist Gets Real about AgTech Challenges


Welcome to another edition of SFTW Convo! This week’s conversation features David Clifford. David is a friend and I had the privilege to work with him at Mineral. David is a data scientist by training.
He was the head of data science at Mineral, has experience working at Metromile (an insurance company), the Climate Corporation (part of Bayer Crop Science), and spent about 10 years at the Australian research organization CSIRO. David got his PhD from the University of Chicago (so we are fellow alums as well!) David currently works as an independent consultant and resides in Ireland.
Summary of the Conversation
In this conversation, David Clifford discusses the intricacies of data science in agriculture, emphasizing the importance of starting with a question and the challenges faced in data quality and bias. He explores the role of AI in agriculture, addressing common misconceptions and the bottlenecks on innovation due to the natural cycles of farming. The discussion highlights the need for effective feedback loops and the potential for AI to enhance agricultural practices while acknowledging the inherent challenges in the industry.
David Clifford discusses various models of innovation in agriculture, comparing the approach of Climate with the ambitious strategies of Mineral. He highlights the importance of understanding customer needs and the specific context of agricultural challenges. The discussion goes into cultural differences in agricultural innovation across the US, and Europe, emphasizing the role of academia in bridging research and commercial applications. David shares insights on the potential impact of AI in agriculture, particularly in cost of production in farming activities, and speculates on future trends in farming, including the challenges of succession planning and the aging farmer demographic.


Build Less, Scale Faster: The Rise of White-Label Platforms
Ag leaders aren’t asking “Can we build it?”—they’re asking “Should we?” White-labeled platforms are helping agribusinesses move faster and deliver on strategy while staying focused. From carbon tracking to digital agronomy, e-commerce, and lab insights, leaders are choosing to scale through their brand, not by building new tech stacks. Customers don’t care who built it—they care that it works. With white-labeled tech, you can go to market fast with your logo, your workflows, and our managed infrastructure behind the scenes.
A data scientist gets real about AgTech challenges
Rhishi Pethe: People talk about data scientists a lot, but what the hell is a data scientist? Outside of just pure technical skills, what makes for a good data scientist?
David Clifford: A data scientist works comfortably with data in all its different forms. I think the definition of a data scientist has shifted over time. When I began my career, a data scientist was essentially a statistician working with a dataset small enough to fit into a computer’s memory.
Back then, the typical process looked like this: “Here’s a dataset, find something interesting in it.” That was the academic approach I was trained in. But once you enter industry, things change. It becomes more like: “Here’s a dataset and a question, can you answer it?” And as you progress in your career, the framing shifts again: “Here’s a question, how do we generate the right data to answer it?”
At that stage, a data scientist’s job involves gathering the right information, often by connecting the dots across multiple sources. You cycle through a process: clean & structure data, visualize it, build models to capture what those visuals show, go back to restructure the data as your exploration comes together, and repeat. With each loop, you gain a deeper understanding of the problem and refine your sense of what the answer might be, and how to support it with evidence.
 -> Communicate. Surrounding all of these is Program.")
Ultimately, the goal is to answer the question clearly, communicate that answer to your collaborators, and ensure the insight influences what happens next.
Later, we might talk about Climate Corp or Mineral. I’ve seen this amazing moment happen over and over. People finally see the data, yield maps they’ve collected for years, displayed interactively on a platform. Suddenly, it’s at their fingertips. They can explore it. And there’s this moment of excitement.
But then the question hits: “What do I do with this? Why does this matter?”
That’s where the real work begins, turning description and visualization into insight, and turning insight into action, with and for the people who need it.
Rhishi Pethe: Yeah, I think this is a good segue. You brought up something important: it’s not just about finding an answer, it starts with asking the right question.
At Climate, people made fun of the stated strategy “Get users, get data, and that’ll somehow turn into dollars.” But when you hear that, you can’t help but ask: What’s the actual question you’re trying to answer there?
What questions were you focused on at Climate? And if there was a struggle, where did that show up?
David Clifford: I joined Climate about a year after Monsanto acquired them. Erik Andrejko, the head of science, oversaw a few different science teams, and he brought me in to lead one of them. My focus was on a product Monsanto had originally developed, something that resembled what Climate was working toward.
The product aimed to offer seeding recommendations: which corn variety to plant and how much seed to use but it wasn’t fully formed and not designed to scale. I don’t recall now what it was called. It seemed like an internal project, something a group had put together after observing Climate’s trajectory and speculating about where it might go. After the acquisition, they folded that product into Climate, but at the time, Climate still operated largely independently.
I came in to lead a team, not to reuse Monsanto’s approach, but to develop our own. We asked: given what we know about a farmer’s field, Farmer John’s or Farmer Rishi’s, along with their historical field data and yield goals, what should they plant? How much seed should they use? And how should they deploy it, at variable rates, in zones, across the field?
Those were the real questions we wanted to answer.
We had some historical yield data, but I was surprised after I joined to realize it wasn’t accessible, even from inside Climate. During the interview process, I had assumed that all that data would be at our fingertips and ready to integrate. But in practice, that wasn’t the case.
What we did have was access to data from Monsanto’s breeding pipeline: trial data from various development stages and demo trials comparing different seed varieties. We pulled that together with Climate’s internal data and used it to build smarter, field-specific seeding recommendations, what to plant, how much, and where to place it for optimal results.
Rhishi Pethe: Yeah, it sounds like the question you started with was a solid one: How do you help a farmer get the best possible outcome based on the information you have?
It’s actually something I discussed with Mike Stern when I spoke to him. When he took on the role of CEO at Climate, I asked him: What assumptions did you make going in that turned out not to be entirely true? One thing he shared was that while the core hypothesis, that data can answer these questions, still holds, the challenge was different. It came down to whether you had enough data. Or the right quality of data. Those were the real constraints when it came to answering that core question.
What did you learn through that process? What made it difficult to answer with confidence?
David Clifford: There were many challenges. As a data scientist, you work with the data you have. Earlier you asked about important skills beyond technical ability, and one that stands out, whether it’s a formal skill or just a common trait among data scientists, is skepticism.

We tend to question the data we’re given. We constantly ask, How did this data come to be? Because we know that data doesn’t just appear, it's not like standing in the field where you can point and say, “That’s 927,” and trust the number. Every number goes through a process before it lands in a spreadsheet or on a dashboard, and that process introduces uncertainty. So we often ask: What’s missing here? How was this data filtered, aggregated, or massaged?
When we tried to understand yield performance, we worked with two types of data. First, we had rigorously structured yield trials, formally designed experiments comparing seed varieties under controlled conditions. Then we had much messier data: broader, real-world datasets from strip trials that a local sales rep, say Joan in a county in Iowa, might set up in a farmer’s field.
That data felt more grounded, more reflective of how crops perform under real conditions rather than in pristine research plots. But it also came with its own set of caveats. Sales reps might design trials to favor the brand they were promoting, giving their seed the best soil or conditions. Some of them would include competitor seeds but subtly bias the trial in favor of their own. So we had to take all that with a grain of salt.
That skepticism fed into questions about whether we could reliably use that kind of data to train or validate models. In the end, we made pragmatic choices, we used what we had and made the most of it.
We also faced external skepticism, especially from farmers. Many saw these tools as just another method to sell Monsanto seed. And in many ways, they weren’t wrong. We had far more performance data on Monsanto brands than on competitor products. We pulled what we could from university trials and other public sources, but the balance was lopsided. So naturally, while some may have questioned whether our recommendations were biased, Climate & Monsanto’s goals were to put the best product on each acre.
So yeah, the question we were trying to answer, What’s the right seed for this field?, was a fascinating one. From a data science standpoint, it required piecing together incomplete, messy, and sometimes biased information. We used the best methods we could and gave the best answer we were able to construct with what we had.
Data and decision making
Rhishi Pethe: So was the challenge really about missing certain types of data? If you'd had access to those specific data sources, would that have opened up the model and made the answers much stronger?
Was it more that you had access to all the data you reasonably could, but the issue came down to quality, confidence, or bias?
David Clifford: That was definitely one component of the challenge. But when I think about the broader set of data we had access to, it included things like what was planted, when it was planted, and how much seed was used. We could pull in weather data that felt like it was at a relatively high resolution. We had coarse soil data from SSURGO, and sometimes we had fertilizer application details.
Still, a lot happens over the course of a growing season that impacts yield. At the beginning, conditions might be ideal, and you're on track for optimal yield. But everything that follows, weather, disease, management decisions, gradually chips away at that potential. Yet we only get to see the outcome at the end: a snapshot of final yield.
We did have some medium-resolution satellite imagery throughout the season, which helped us make sense of what happened, after the fact. You could use it to explain why a field underperformed or exceeded expectations. Maybe there was a disease outbreak, or damage from a storm, and you could see it in one of the images. But you couldn’t use that imagery to predict forward. It wasn’t useful for forecasting or making proactive recommendations.
So there was always this sense that we were missing data. There was never quite enough. You always wanted one more variable, something else to strengthen the model. But the reality is: when you build a model for farmers, you have to use the information they’ll have on hand at the time they’re making decisions.
That meant building the model around what’s available months before planting. Farmers order their seed long before they know if it’ll be a wet spring or a dry one. You can’t rely on real-time planting conditions because that information simply doesn’t exist yet. So the challenge becomes: Given what’s knowable when the seed decision is being made, how can we generate the best recommendation possible? And that’s what we worked with.
Rhishi Pethe: This feels like an intractable problem. Farmers will always need to buy seed in advance, because of supply chain timelines, planning cycles, and everything else that goes into preparing a season. But if we can’t predict the weather with a reasonable degree of confidence, that decision is always going to carry risk.
So does that mean the problem can’t truly be solved unless we dramatically improve our ability to forecast weather and other variables far in advance? That’s one possible path.
The other approach is to shift the decision point, to let farmers buy seed at the last minute, once they have higher confidence about what the season might bring. But that would require massive changes to how the supply chain operates. Neither option is easy.
David Clifford: Yeah, I don’t think the supply chains are always efficient enough to get you exactly what you want at the moment you want it. And there’s definitely a scramble some years, like when a particular Dekalb variety becomes especially popular, and everyone rushes to get it.
But it’s not an intractable problem. There’s actually a lot of value in looking backward, at the end-of-season yield, and trying to understand which parts of your management decisions contributed to that result. If a farmer runs experiments on their own field, like splitting it between two different seed varieties or planting in a specific pattern, that creates a learning opportunity. For example, FarmTest helps you design and implement your own experiments in the field and get statistically significant results.
We encouraged a lot of that experimentation. And when farmers engaged in it, we could look back and help interpret the results. That kind of retrospective analysis helped them figure out what worked and why, and those insights carried forward into the next season.
Even after you’ve made your seed purchase, you haven’t locked in exactly how you’ll deploy it. You might have a limited amount of a certain variety, and as planting day approaches, you can make decisions about where to use it. Maybe you’ll plant more of it in low-lying pockets between ridges or hold some for higher ground, depending on how wet or dry the season is shaping up.
There’s a lot of value in that kind of flexibility, and I think Climate helped farmers start to recognize that. It gave them tools to reflect, to plan smarter the next time. Of course, there’s always more we wanted to do, more we could have done, but it was a meaningful step forward.
Rhishi Pethe: So the farmer makes an aggregate decision a few months in advance, choosing the varieties they’re going to buy and in what quantities for the season. But the actual decisions about where to plant each variety and when to plant them happen closer to the operation itself. That timing gives the farmer some flexibility to adapt based on emerging conditions.
David Clifford: Yeah, I think so. One thing I never figured out during my time there, and I would’ve loved to, is what actually goes into a farmer’s decision-making process after they get a recommendation from the product. We could tell them what to plant and how much to use, but that was just one piece of a much larger puzzle.
These big growers don’t make decisions in isolation. Throughout the growing season, Monsanto’s sales reps spend time building relationships with them. They host facility tours, offer agronomy advice, and generally stay close. Farmers get input from a lot of different sources, advisors, peers, field reps, and I suspect that advice often carries more weight than what the product recommends.
I’d love to know how many farmers actually follow the product’s recommendation versus how many lean into what the sales team suggests. My guess is that many follow the agronomy or sales guidance, especially since the sales folks want that relationship to be the reason farmers stay engaged, to feel like the trust and time invested matter.
That dynamic always fascinated me. The influence behind the scenes, the human layer behind what seems like a data-driven decision.
Is AI hype or real?
Rhishi Pethe: You’ve talked a lot about building models, and obviously AI is in full hype mode right now, dialed up to 11. Since you’re deep in this space, I’m curious: what are some of the biggest misunderstandings people have about AI in agriculture?
When you talk to people, whether they’re investors, farmers, or just curious observers, what are some of the assumptions you hear that make you think, “Oh no, that’s not how this works at all”?
David Clifford: In general, not just in agriculture, people tend to fall into one of two extremes when it comes to AI. On one side, you’ve got the “AI will save us” crowd, convinced it can solve every problem, even the non-technical ones. On the other side, there are the skeptics who write it off completely: “This thing is useless.” It’s easy to support either view, especially when you see AI confidently get something absurdly wrong, like miscounting the number of A’s in “banana” and insisting the answer is four or seven.
So it’s tempting to believe it’s either magic or a joke. But the truth, as always, sits somewhere in the middle.
I really appreciate thinkers like Ethan Mollick. You may have seen some of his recent posts, he made a great point that even if AI development stopped today, we’d still have years of untapped value to mine from what already exists. I agree with that. We’ve barely scratched the surface in terms of applying these tools effectively.
<https://x.com/emollick/status/1866982142217236651>
That’s true across industries, and especially in agriculture. I’m particularly interested in how we might use language models more in ag, since that’s where most of the AI momentum is happening right now. I’ve seen early examples, chatbots that act like agronomy advisors, offering Q&A-style interactions. Some of them are promising, both here in the U.S. and internationally.
That said, I don’t know how widely they’re being used or how much traction they’ve actually gained. I’ve read your white paper on this, Rishi, your case studies with Bayer and others are excellent. But I still wonder what the sustainable business model looks like in this space. There’s a lot of potential, but also a lot of misconceptions and hype on the Ag side of AI.
Rhishi Pethe: You recently spoke at the AI & Ag conference in Mississippi. One line stood out to me: “Move fast, build more, try not to break critical things.” That really stuck with me, because it’s the opposite of Facebook’s old mantra: Move fast and break things.
At first glance, these ideas seem like they’re in conflict. Move fast. Build more. But try not to break things, especially critical things. How do you prioritize speed, scale, and responsibility when you're working in a space like agriculture, where the stakes are high?
David Clifford: That’s a good question. When I presented that part of the talk, I wanted to convey this idea of vibe coding, that feeling of sitting alongside your AI coding assistant, tossing things together in the flow, and suddenly, it works. It’s casual, it’s collaborative, and it feels almost magical when it clicks.
At the same time, I found myself reflecting on what building tech looked like ten years ago, back when I was at Climate. Back then, we had so many engineering teams, each one with a front-end engineer, a back-end engineer, a QA person, a designer… it was a big crew. Fast forward to now, and if someone tried to build what Dave Friedberg put together, they could do it with a much smaller, sharper team. But here’s the key: that team needs to be dialed in. They need to know what they’re doing.
You can’t just describe the whole Climate platform in a single prompt and hit “go.” That’s what some of the early vibe coders did. And sure, they got something running, but they also opened up massive security holes and burned through cloud budgets. That was part of the point I was making, people running wild with AI without thinking about the consequences.
But if you’ve got experienced folks on a small, focused team, people who understand software engineering, machine learning, and product constraints, you can go straight to the problem. You don’t waste time. You don’t ship something embarrassing. You can stay aligned, move fast, and focus on what really matters. That’s one piece of today’s AI hype that I do think is real.

Another thing that feels very real, especially compared to ten years ago at Climate or even five years ago at Mineral, is how little data you need now to get started. At Mineral, every time we built a new model, we basically started from zero. New architecture. New data collection. At Climate, deep learning hadn’t even really landed yet. I remember someone trying to build a disease detector. They brought in folks from Monsanto to help label images, and when they finally rolled out the dataset, it had 150 images. That was it. And the guy building the model just lost it in the meeting, he said, “I can’t do anything with this.”
Sure, 150 images is still small, but today, if you’re fine-tuning a model that’s already trained on massive foundational visual datasets, you can do something with that. You can transfer knowledge and get meaningful results in new settings with far less effort than before.
That’s a big shift. Today’s AI tooling lets us move faster with smaller teams, smaller datasets, and clearer focus. That’s not hype. That’s a real change.
What dictates the pace of innovation?
Rhishi Pethe: Let me offer a bit of a counter, not to disagree, but just to explore the idea more deeply. Someone might say, “Look, this is agriculture. Plants grow at their own pace. You can’t rush a fruit to ripen faster. That’s just biology.” And sure, maybe genetics can eventually help with that, but even then, we’re talking about timescales measured in years.
So if I’m an investor, an agribusiness executive, or even a farmer, how should I think about the pace of innovation in this space? Should I expect things to move faster just because AI allows for smaller, more agile teams and lower-cost experimentation? Or are there still fundamental, rate-limiting factors, biological, ecological, even regulatory, that keep agriculture on its own timeline, no matter how fast the tech world moves?
David Clifford: Yeah, I think the annual cycle in cropping creates a natural but limiting pace in agriculture. That rhythm shapes how you build and test anything. You might deploy something new, but it typically only gets used once during a growing season. That limits your ability to iterate, especially if you want to incorporate new data or insights quickly.
To get around that, we focused on data collection. As we dug deeper into problems, we expanded our labeled datasets and refined our models. But still, that yearly cadence remains a fundamental constraint, one that shapes how investors evaluate startups in this space. It slows iteration, and by extension, slows innovation.
Recently, I’ve been learning more about the livestock side of agriculture, and the dynamics are quite different. Sure, animals have longer lifespans than crops, but the frequency of measurement is often much higher. In dairy or beef production, for example, farms might assess an animal’s weight gain weekly or track milk quality daily, sometimes even multiple times a day.
In those settings, you can build models that connect feed quality, activity levels, and health indicators with outputs like milk composition or yield. And because you’re getting data continuously, you can iterate rapidly. That opens the door for much faster development cycles and more agile decision-making.
From an investment perspective, that makes the animal side more compelling. And from a climate perspective, the impact potential is also much greater, especially when you factor in the methane emissions from cattle. That’s why I find the livestock space increasingly interesting. It’s also a big area of focus here in Ireland, where dairy and beef play such a large role in agriculture.
Compare that to the cropping side, and the difference in cadence is stark. When you apply AI in areas like ad targeting, e-commerce, or video recommendations, you can iterate almost instantly. I used to bring this up when interviewing people for Climate or Mineral. I’d ask them to consider the reality of the data, its size, the frequency of collection, the feedback loops. At a place like Google, a data scientist can push a new model into an A/B test on Friday and return on Monday with results based on millions of users. That kind of feedback loop simply doesn’t exist in cropping.
So yeah, that’s one of the big constraints, but also one of the big differences, when you’re applying AI in agriculture.
Rhishi Pethe: I’d say the pace of the feedback loop plays a major role in determining how quickly we can improve these models. That feedback loop directly affects how fast we can iterate, update, and push toward better outcomes, and ultimately, how quickly we can productize and commercialize the solutions.
So even if the technology is ready, the speed at which we can gather meaningful feedback becomes a key limiting factor. That’s what shapes the real timeline for innovation in agriculture.
David Clifford: And of course, data availability plays a big role in shaping that pace. But it’s not just the data, it’s also the entire data science process. Even after we build a model, we still have to deploy it into a production environment. Then we need to monitor how people are using it and whether it's actually working as intended.
At some point, we’ll likely discover that something needs improvement, maybe a general refinement or a very specific fix. To do that, we need to source more information, retrain, adjust the model, and redeploy. That means jumping back into the cycle.
If that full data science or machine learning engineering cycle takes weeks, or even months, then sure, the annual crop cycle isn’t the only bottleneck. We’re slowing ourselves down too. So the goal is to reduce that internal cycle time as much as possible. The more times we can go through that loop, and the more of it we can automate, the faster we can iterate and improve our models.
That’s how we create real momentum, even within the natural constraints of agriculture.
Singles or Home runs?
Rhishi Pethe: You worked at Climate, where the innovation model was tightly linked to Bayer and Monsanto. It felt very incremental, focused on helping farmers make slightly better decisions, step by step. That’s a valid and potentially high-impact approach, especially when scaled across millions of acres.
Then at Mineral, part of X, the mindset shifted. It was all about swinging for the fences, big bets, ambitious tech, deep science.
Both approaches had pros and cons. Mineral no longer exists. Climate has pulled back. When you look back, how do you compare and contrast those two innovation models?
David Clifford: I think innovation model suitability in AgTech is incredibly case-specific. If there were a single obvious model that worked, everyone would be using it. But the reality is, there are multiple approaches, and that’s a good thing. The more diverse the thinking around innovation in agriculture, the better.
What really matters is choosing the right segment of agriculture to focus on. You have to know your customer deeply, understand who they are and what problems truly matter to them. Then, you need to find a way to solve that problem, whether it’s in the way Climate tried, or in a more fundamental, system-level shift like what Mineral attempted with deep learning and data collection.
Once you’ve solved the technical challenge, and that’s only the beginning, you still have to make sure it can scale. And scaling in agriculture isn’t straightforward. It’s slow, fragmented, and often regionally nuanced. After that, you have to prove your solution works, earn users’ trust, deploy it, and figure out distribution. The technical challenge is just the first step; it’s everything that comes after that determines whether you can build a lasting business.
So when people look at what worked or didn’t work at Climate, or at Mineral, or anywhere else, it’s important to remember that context matters. What failed in one setting might succeed in another, or vice versa. These outcomes are deeply tied to timing, structure, and execution.
Take Climate, for example. You have framed it as delivering only incremental value. But from Dave Friedberg’s point of view, it was a massive success. And from Monsanto’s perspective, especially after the Bayer acquisition, it was clearly valuable. Climate became a global product, deployed across many countries and acres, bundled with seed sales. That’s not a small win. That's the real scale.
But at the same time, many people left Climate soon after. Maybe that’s a reflection of how fast things were moving in the early years, there was momentum, urgency, energy. When the work became more incremental, it attracted a different kind of person. That’s not a failure; it’s just a shift in phase and in mindset.
Rhishi Pethe: You said the natural feedback loop sets the pace for progress. Let’s take strawberries as an example, you’ve worked on that quite a bit.
With strawberries, you get yield feedback every few weeks. You can assess flavor and shelf life at about the same pace. So when you think about all these dimensions, yield, flavor, shelf life, and cost of production, it seems like the first three offer similar feedback cycles, while harvest cost is tied more to labor and logistics.
Do you think AI will have a bigger impact in areas like yield and flavor, simply because the feedback loop is tighter? Or does the cost side also offer enough real-time data to enable rapid learning and improvement?
David Clifford: Yeah, I think there are real opportunities for AI across all four of those dimensions. If we go back to that Ethan Mollick quote we discussed earlier, the biggest near-term impact might actually come from applying AI to back-office operations, reducing production costs, and improving how ag businesses run day-to-day. That’s often the unglamorous side of agriculture, but it’s where efficiency gains can be immediate and meaningful.
Of course, areas like yield optimization, flavor profiling, or breeding strategies also offer huge potential for AI. But they often require integration with deeper layers of science, genetics, plant biology, chemistry. AI will play a role there, but it won’t act alone.
That said, I genuinely believe the “killer” AI use case in agriculture might surprise everyone. It might not come from the obvious spaces like robotics or prediction models. It could emerge in something simple but deeply impactful, maybe a back-end system no one’s paying attention to yet. That’s often how real transformation shows up.
Here in Europe, regulation plays a huge role in shaping how farming works. And if anything, it’s only getting stricter. That’s in contrast to the U.S., where regulatory pressure might actually be easing in some areas. But here, it’s pushing change, not just locally, but globally.
Take Brazil, for example. If you're a beef farmer and you want to sell into the European market, you have to adjust your practices to meet EU standards. That’s a powerful incentive, and it’s forcing farmers around the world to stay on top of constantly evolving regulations.
But here’s the reality: farmers want to farm. They want to be out in the field with their animals, on the tractor, in the rhythm of the land. No one gets into farming to sit in an office filling out compliance forms. That’s not why they do it.
So systems that help farmers manage regulation, that simplify or automate those processes, have huge potential. This is where AI could really shine. These tools wouldn’t just save time; they’d pay for themselves quickly. And most importantly, they’d give farmers the freedom to focus on what they do best: innovating in husbandry, crop management, and sustainable practices.
That’s where I think a lot of the value might come from, not flashy, futuristic use cases, but practical, grounded tools that remove friction from farming life.
Rhishi Pethe: Yeah, the idea is about removing non-farming tasks, compliance, paperwork, reporting, so farmers can focus on what they actually came to do: grow food, care for animals, and manage the land.
David Clifford: Yeah, AI can absolutely help smooth that process out. At the end of the day, the farmer is still responsible for what goes on those forms, whatever the AI suggests, they’re signing off on it. But instead of staring at a blank page or a massive form full of empty boxes, they’re starting with something. A draft. A head start.
That makes a huge difference.
Sure, they’ll still need to connect the dots between field activities, regulations, and reporting requirements. But that’s where sensors and connected technologies come in. Those tools will provide context. The AI can weave those inputs into something useful.
And honestly, if it makes the experience more enjoyable for the farmer, less paperwork, more time in the field, that alone is a big win. That matters. Because when the tools respect the way farmers actually want to work, adoption follows.
University Collaboration
Rhishi Pethe: When you were at Mineral, you were leading those university relationships. In the U.S., there’s this long tradition of land-grant universities and ag extension programs, deeply tied to agriculture and public research.
What do you think the AgTech industry and universities could be doing better together? What are some of the persistent challenges that stand in the way of turning research into real-world value?
David Clifford: In the U.S., especially outside of the land-grant university or academic setting, there’s a massive amount of publicly available data that fuels AgTech innovation. You’ve got weather data, satellite imagery, USDA reports... a lot of startups build on top of that infrastructure. Whether or not every effort succeeds, that data has definitely spurred significant investment and usage. Unfortunately, some of that openness seems to be changing right now, and not in the right direction.
At Mineral, our engagement with academia was fascinating, and also, at times, challenging. I wouldn’t call it a complaint exactly, but here’s what would happen: You’d read some papers, identify promising research, and reach out to the university to explore a potential collaboration or licensing deal. But as soon as they heard "Google" or "Alphabet" calling, the dollar signs lit up. Some researchers assumed they were about to retire on the spot.
So we had to manage expectations pretty quickly.

What helped was Alphabet’s existing umbrella agreements with a number of universities. These made it easier to formalize partnerships. These pre-negotiated agreements allowed us to move quickly once we found the right researcher.
And really, finding the right person made all the difference.
The most productive relationships came when we met researchers who were genuinely motivated to see their work applied in the real world. They weren’t just chasing funding, they wanted to push their technology further, answer real questions, and involve their students in meaningful ways. Often, their postdocs and PhD students joined us for internships, got startup experience, and in a few cases, might’ve ended up working at Mineral full-time if the project had continued. It was a win-win.
Now, some universities take IP licensing incredibly seriously. They’ve built entire administrative teams around managing it. But that also means the process can slow down under the weight of internal bureaucracy. And unless the licensing office sees a big enough financial opportunity, they might not prioritize the work.
That’s where finding the right academic partner becomes crucial. If they’re motivated, they’ll work with you, and often push internally on your behalf, to navigate the university’s systems and policies in ways you, as a startup or corporate partner, simply couldn’t do alone.
Demographic changes in farming
Rhishi Pethe: Here in the U.S., we often hear that a wave of older farmers is about to retire, and as the next generation steps in, the average age of farmers will start to come down.
But what you’re saying suggests the opposite, that the average age might actually keep rising. That’s interesting. It implies we’re not seeing enough new entrants to offset the retirements, or that the handoff isn’t happening as quickly or broadly as people expect.
David Clifford: Here in Ireland, the average age of farmers has been rising steadily. In fact, it’s gone up by about ten years in just the past decade. That tells you a lot. Very few new people are entering the profession.
And the barriers to entry are enormous. The cost of getting started in any aspect of farming is incredibly high. Unless you inherit land, it’s hard to even imagine how someone breaks into this space today. You really have to be deeply passionate about farming to make it work, because from a financial and structural standpoint, the odds are tough.
Rhishi Pethe: In any market where you expect a lot of innovation, you typically see low barriers to entry and low barriers to exit. If you want to jump in, you can. If you want to leave, you can. The fluidity fuels experimentation and change.
But in agriculture, it feels like we have the opposite. The barrier to entry is incredibly high, land, equipment, capital, regulation, and the barrier to exit is also high. If you’re a fifth-generation family farmer, you carry the emotional and cultural weight of that legacy. You don’t want to be the generation that ends the line.
That dynamic creates real drag on innovation, and it’s not talked about enough.
David Clifford: A lot of farmers’ children aren’t signing up to take over. It’s a real issue, what they call succession planning. And it gets a lot of attention for good reason. It’s a tough situation on both sides. Often, the next generation doesn’t want the farm, or at least not while their parents are still deeply involved. At the same time, the older generation struggles to let go. And who can blame them? It’s not just a business, it’s their identity, their life’s work.
I’ve seen it up close. A good friend of mine retired from dairy farming a few years ago. We’ve had long conversations as I’ve tried to learn more about the sector. And every time we talk, there are tears. Giving up the farm, selling the herd, it broke his heart. He knew it was the right decision, but that didn’t make it any easier.
Succession in farming isn’t just a logistical handoff. It’s an emotional one. And that makes it one of the hardest transitions in agriculture.
Rhishi Pethe: I was out visiting some sweet potato farms last week, and that exact issue came up. I spoke with a farmer whose family has been working that land for four generations. I asked him directly, “Your kid’s 15, do you think he’ll be farming in 10 or 15 years?” And the farmer just said, “I don’t think so. But if that happens, it’ll be his decision to stop, not mine.”
Farming in 2035
Rhishi Pethe: So based on everything you’ve talked about, data, AI, regulation, decision-making, let’s fast forward a bit. It’s 2025 now, but imagine we suddenly drop you into 2035 or so. Looking eight to ten years ahead, how do you think farming or agriculture will look different?
David Clifford: Yeah, things are definitely shifting. Some trends feel inevitable at this point: fewer farmers, older farmers, larger farms. And in many regions, especially Europe, regulation is only increasing. That combination creates real pressure.
I think we’ll see a growing emphasis on food and farming security here in Europe. Policymakers have already started softening some of the more ambitious Green Deal requirements. There’s a recognition now that farming needs to become more professionalized if we’re going to keep up, especially with fewer people managing more land.
So I expect more automation, but not just in the flashy robotics sense, more integrated systems that support decision-making, compliance, and scale. Here in Ireland, for example, a lot of farmers work part-time. They might have a professional job and manage a beef herd on the side. That works today, especially when the herd doesn’t demand constant attention.
But with tighter regulation, that model may not be sustainable. At some point, people may need to hand off those operations to full-time professionals who can manage the complexity.
That’s where I see things heading. What patterns are you seeing on your end?
Rhishi Pethe: On the row crop side, we’ve seen this constant push toward bigger and faster equipment. But I suspect that trend might start to plateau with the rise of autonomy.
Instead of relying on a single 700-horsepower, million-dollar machine with an operator inside, we might shift toward smaller, more nimble autonomous machines. They wouldn’t need a human on board, maybe just one person managing or "joysticking" several of them remotely.
That model could fundamentally change how we think about scale, labor, and field operations.
David Clifford: Yeah, I like that vision for the future too. I don’t often think about the political side of farming, but as farmers become fewer, there’s a valid concern that their political influence could shrink. That said, I don’t expect it to disappear.
In Europe especially, farmers still form a powerful political bloc. When they drive their tractors onto the motorway and bring traffic to a halt, people pay attention. There's still a cultural and emotional connection to farming here, and in many parts of the world. It’s not a distant, abstract profession. Most people aren’t that far removed from the land, and there’s still a romantic view of what it means to be a farmer.
When farmers are hurting, they often receive public sympathy and support. But at the same time, in many regions, farming isn’t seen as a profession of choice. It’s something people do because they inherited the land or because there weren’t other options.
It’ll be interesting to see how that shifts, especially as demographics evolve and expectations around work and identity change globally. Will farming regain its appeal? Will new generations take it on with pride and purpose? That’s still an open question.
Rhishi Pethe: Anyway, thanks again. I really appreciate the conversation.